
The Ultimate Observability Duo for the Modern Data Stack
With Sifflet fully integrated into your Databricks environment, your data teams gain end-to-end visibility, AI-powered monitoring, and business-context awareness, without compromising performance.
Why Choose Sifflet for Databricks?
Modern organizations rely on Databricks to unify data engineering, machine learning, and analytics. But as the platform grows in complexity, new risks emerge:
- Broken pipelines that go unnoticed
- Data quality issues that erode trust
- Limited visibility across orchestration and workflows
That’s where Sifflet comes in. Our native integration with Databricks ensures your data pipelines are transparent, reliable, and business-aligned, at scale.

Deep Integration with Databricks
Sifflet enhances the observability of your Databricks stack across:

Delta Pipelines & DLT
Monitor transformation logic, detect broken jobs, and ensure SLAs are met across streaming and batch workflows.

Notebooks & ML Models
Trace data quality issues back to the tables or features powering production models.
Unity Catalog & Lakehouse Metadata
Integrate catalog metadata into observability workflows, enriching alerts with ownership and context.
Cross-Stack Connectivity
Sifflet integrates with dbt, Airflow, Looker, and more, offering a single observability layer that spans your entire lakehouse ecosystem.
End-to-End Data Observability
- Full monitoring across the data lifecycle: from raw ingestion in Databricks to BI consumption
- Real-time alerts for freshness, volume, nulls, and schema changes
- AI-powered prioritization so teams focus on what really matters
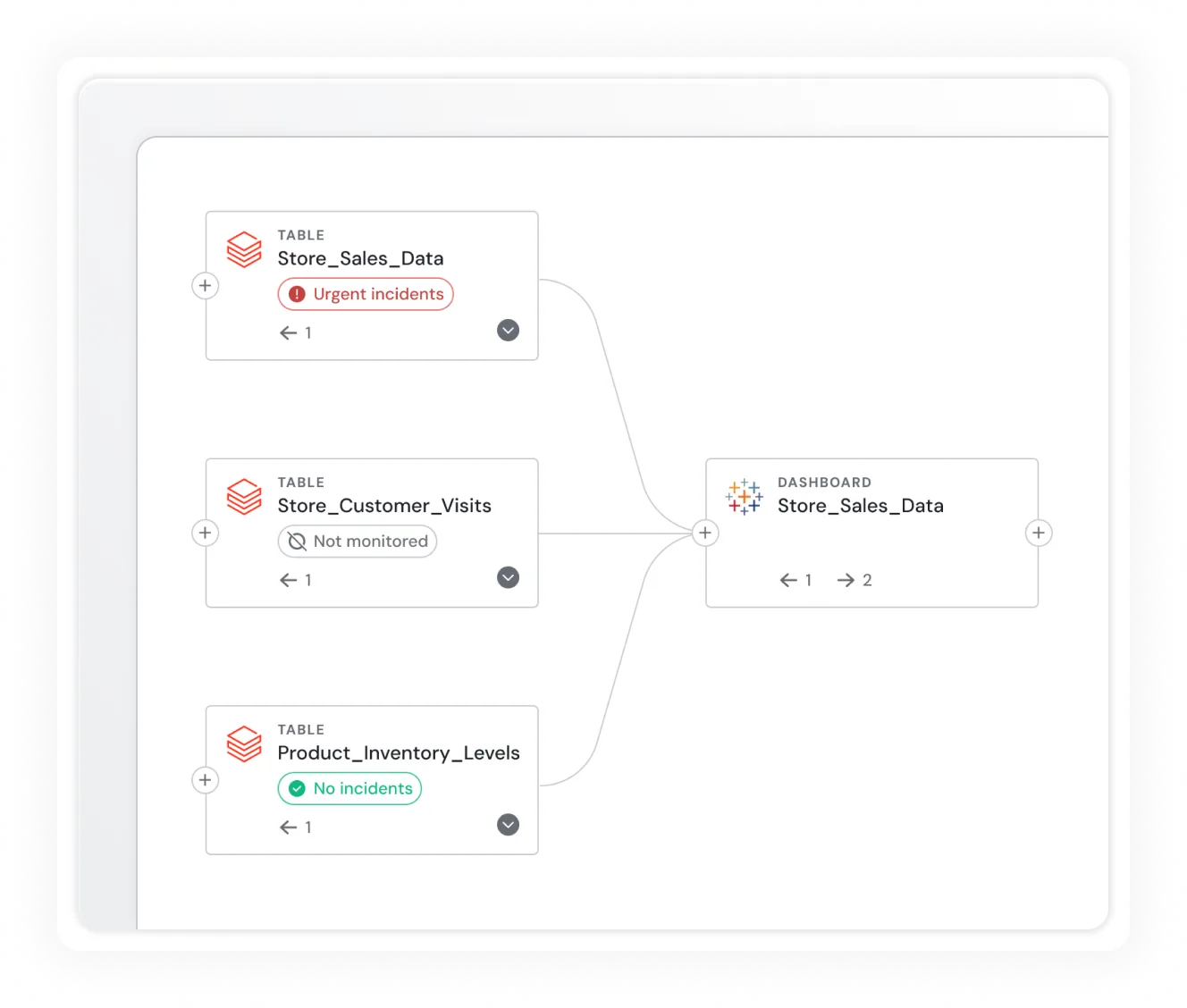
Deep Lineage & Root Cause Analysis
- Column-level lineage across tables, SQL jobs, notebooks, and workflows
- Instantly surface the impact of schema changes or upstream issues
- Native integration with Unity Catalog for a unified metadata view
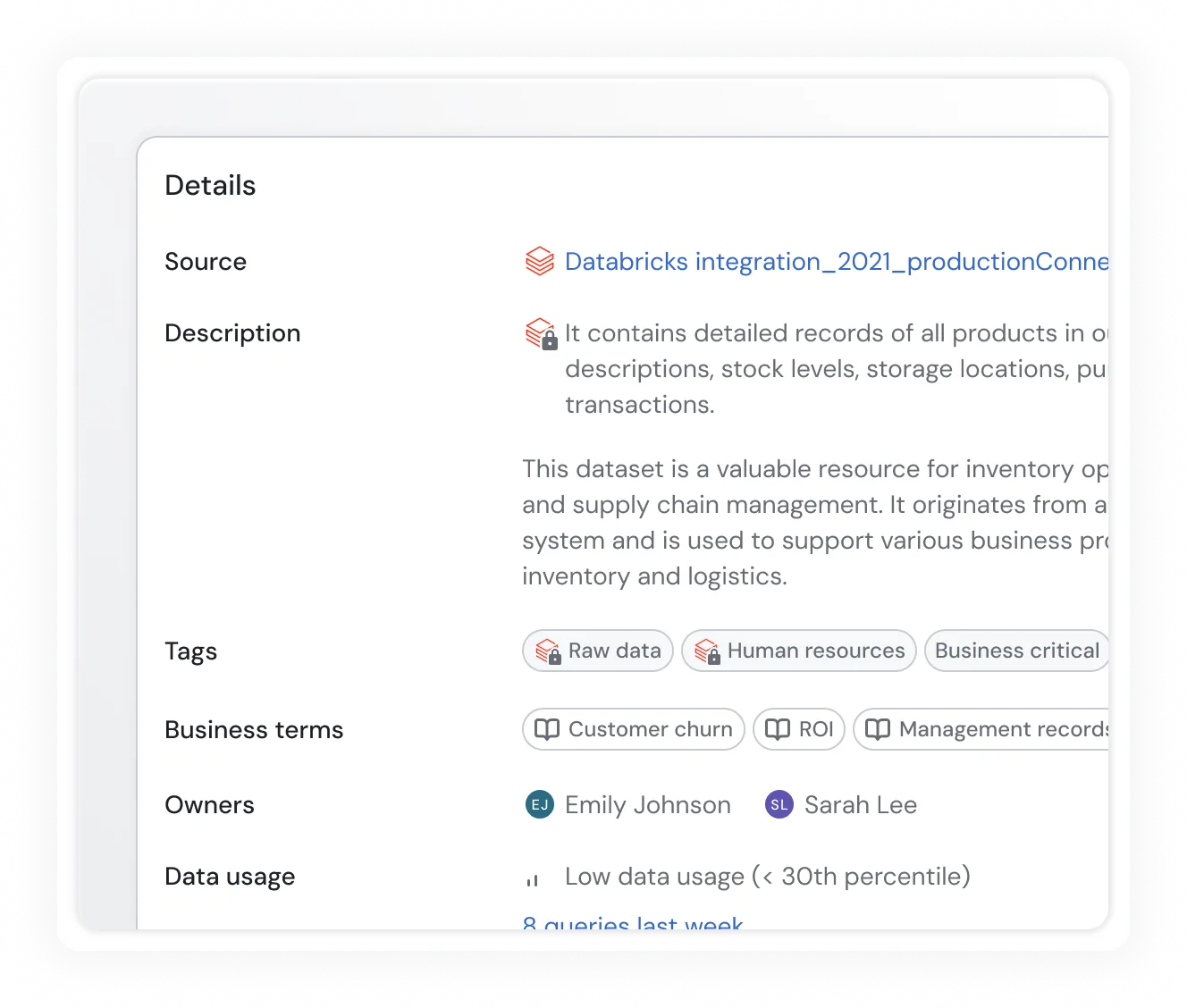
Operational & Governance Insights
- Query-level telemetry, access logs, job runs, and system metadata
- All fully queryable and visualized in observability dashboards
- Enables governance, cost optimization, and security monitoring
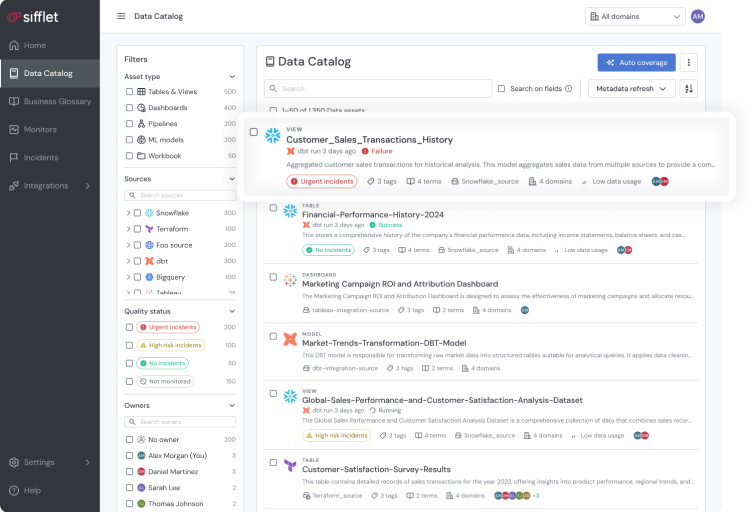

Native Integration with Databricks Ecosystem
- Tight integration with Databricks REST APIs and Unity Catalog
- Observability for Databricks Workflows from orchestration to execution
- Plug-and-play setup, no heavy engineering required
Built for Enterprise-Grade Data Teams
- Certified Databricks Technology Partner
- Deployed in production across global enterprises like St-Gobain and or Euronext
- Designed for scale, governance, and collaboration
“The real value isn’t just in surfacing anomalies. It’s in turning observability into a strategic advantage. Sifflet enables exactly that, on Databricks, at scale.”
Senior Data Leader, North American Enterprise (Anonymous by Choice but happy)
Perfect For…
- Data leaders scaling Databricks across teams
- Analytics teams needing trustworthy dashboards
- Governance teams requiring real lineage and audit trails
- ML teams who need reliable, explainable training data


What impressed us most about Sifflet’s AI-native approach is how seamlessly it adapts to our data landscape — without needing constant tuning. The system learns patterns across our workflows and flags what matters, not just what’s noisy. It’s made our team faster and more focused, especially as we scale analytics across the business.


"Sifflet has been a game-changer for our organization, providing full visibility of data lineage across multiple repositories and platforms. The ability to connect to various data sources ensures observability regardless of the platform, and the clean, intuitive UI makes setup effortless, even when uploading dbt manifest files via the API. Their documentation is concise and easy to follow, and their team's communication has been outstanding—quickly addressing issues, keeping us informed, and incorporating feedback. "


"Sifflet serves as our key enabler in fostering a harmonious relationship with business teams. By proactively identifying and addressing potential issues before they escalate, we can shift the focus of our interactions from troubleshooting to driving meaningful value. This approach not only enhances collaboration but also ensures that our efforts are aligned with creating impactful outcomes for the organization."


"Having the visibility of our DBT transformations combined with full end-to-end data lineage in one central place in Sifflet is so powerful for giving our data teams confidence in our data, helping to diagnose data quality issues and unlocking an effective data mesh for us at BBC Studios"


"Sifflet has transformed our data observability management at Carrefour Links. Thanks to Sifflet's proactive monitoring, we can identify and resolve potential issues before they impact our operations. Additionally, the simplified access to data enables our teams to collaborate more effectively."

"Using Sifflet has helped us move much more quickly because we no longer experience the pain of constantly going back and fixing issues two, three, or four times."








Frequently asked questions

Want to try Sifflet on your Databricks Stack?
Get in touch now!




-p-500.png)
